

Mesh Shading(Asteroids)
这是GDC2019上NVIDIA给的一个关于mesh shading的talk。mesh shading是一套新的shading pipeline,在这个talk里面他们结合了这个名为Asteroids的demo来介绍这套pipeline。这个demo的特点是geometry比较复杂,数据量特别大。视频链接:https://www.youtube.com/watch?v=CRfZYJ_sk5E
Mesh Shading Overview
Overview
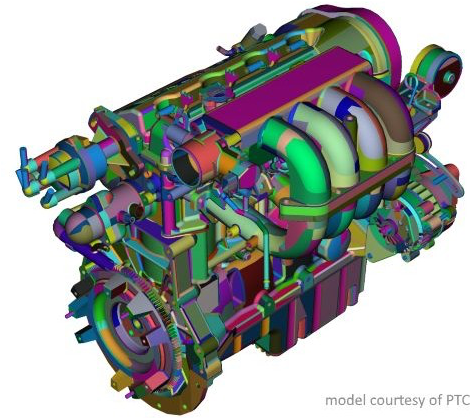
- 利用mesh shading我们可以将一个复杂的geometry分成多个小块的mesh,这些小块称为meshlet;以上图为例,不同颜色的部分是不同的meshlet;因为meshlet足够小,所以可以尽量地直接通过pipeline处理数据,而不用把数据缓存到高级的cache上或者去主存读取数据;
- 另外,mesh shading提供了一个更像compute shader的方式去处理geometry。写过compute shader或者cuda的同学可能会比较熟悉cooperative thread array的概念。在这些程序里有一个thread的数组,你可以控制不同的thread去做不同的事情;正因为它的灵活性,所以可以用来优化geometry的拓扑结构,具体做法之后会讲到。
A New Pipeline

上面是传统pipeline和mesh shading pipeline的一个对比。图中深绿色部分是fixed-function,例如光栅化的阶段;浅绿色是可编程的阶段,例如vertex/geometry/pixel shader。mesh shading pipeline在raster和pixel shader这两个阶段是和传统pipeline一样的,不同在于之前的阶段改为一个可编程的mesh shader;mesh shader前面可以加一个task shader阶段来更灵活地生成并执行mesh shader。
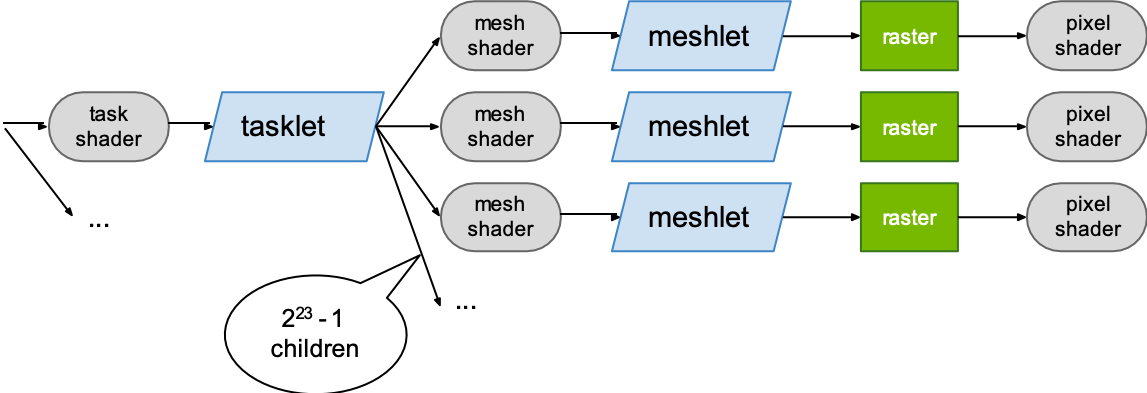
上面这个图更加清楚地表明了task shader和mesh shader之间的关系。具体来说,task shader可以产生指定数量的mesh shader,最多有约8.5million。task mesh向mesh shader传递的数据称为tasklet;对应地,mesh shader和raster之间传递的数据称为meshlet,meshlet中包含了一些primitive的信息。
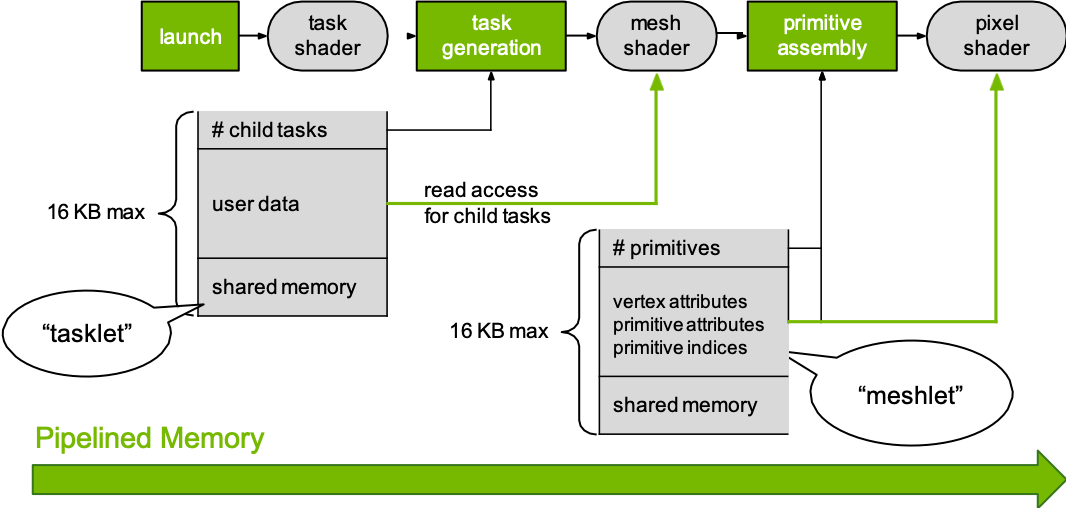
上面这个图进一步表明了各个阶段之间传递的数据。tasklet最多有16kb,数据的第一部分是想要产生的mesh shader的数量;剩下的部分可以用作user data,用来保存lod之类的;还可以设置一定的shared memory,这个shared memory的作用跟compute shader/cuda里面的一样,共享给所有的thread访问。之后会产生指定数量的mesh shader,每个mesh shader的输入都是一样的tasklet,输出也就是meshlet。对应的,meshlet里面存的第一项数据是需要输出的primitive的数量(多少个三角形多少条线),然后是各种顶点属性(position、normal),比较特别的是还可以指定per primitive的属性,比如整个三角形的颜色;接着当然还要要对应的indices;最后剩余的空间也可以用作shared memory。
Mesh Shader in DX

以上是如何在DX中使用mesh shader的示例,没有什么特别需要讲的。

最后绘制阶段的调用跟一般的draw call有所不同,这里调用的是一个特别的DispatchGraphics函数,第一个参数和一般的drawcall一样,第二个参数代表你要使用的task shader/mesh shader的数量。如果这里是5的话,之后shader里面获取的group id就是从0到4的值(依然跟compute shader很像)。
Cooperative Thread Arrays
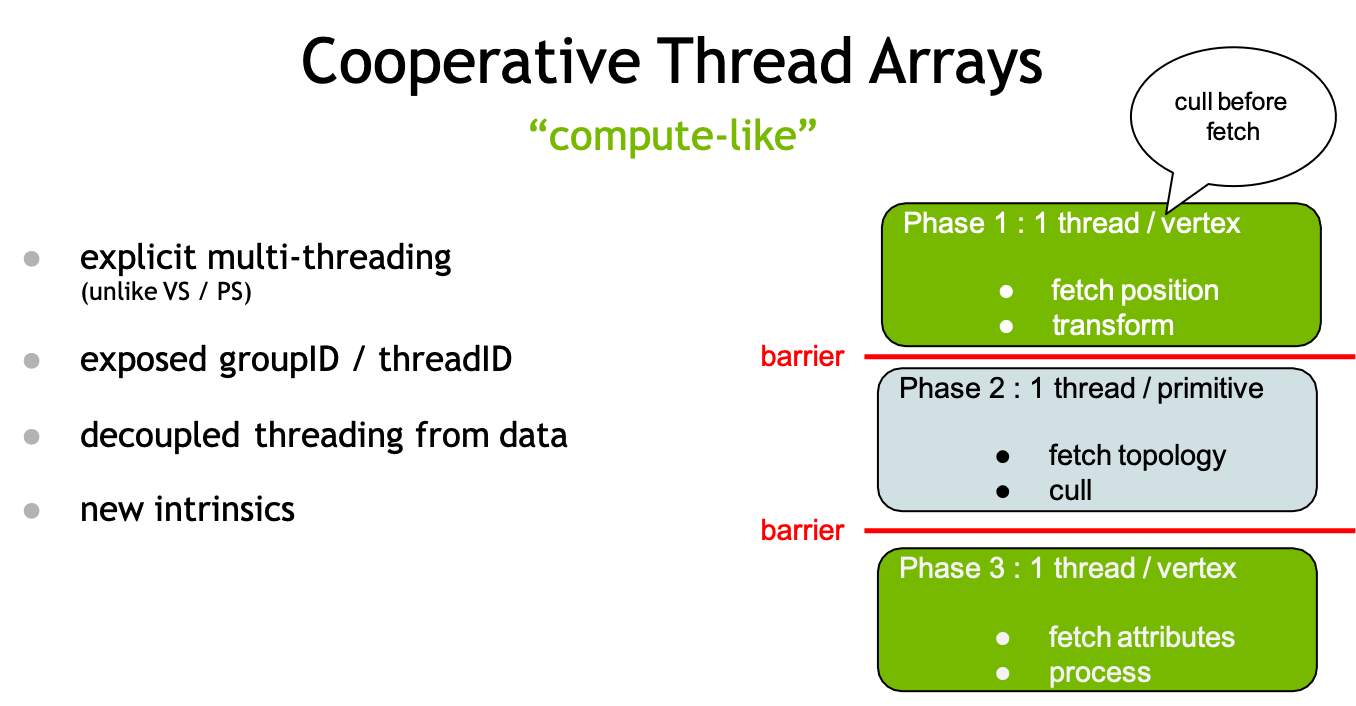
大致介绍完mesh shading pipeline之后,我们来看一下为什么这种cooperative thread array的模式非常有用。
不像之前的pipeline,mesh shading的这种pipeline提供了一种显式的多线程。在之前的vertex shader里,每个thread就是各干各的,只能让它以同样的方式处理单个vertex上的数据;但是新的pipeline下groupID和threadID是暴露出来的,就像在compute shader,每个thread可以做不同的事情,也可以合作;这样方式实际上就是解耦了data和thread。
右图是一个例子:这套pipeline使得我们现在可以在fetch数据之前完成culling。在传统的pipeline中,每个vertex shader都要fetch全部的vertex attribute,实际上大部分的vertex都会被culling掉,然而还是无意义地fetch了这些vertex attribute做计算;而在这套新的pipeline下,我们可以实现cull before fetch,它的实现可以分成三个阶段。
- 每个thread对应一个vertex,fetch position然后计算transform;
- 在所有的thread完成后,进入第二阶段,这次是对每个thread对应一个primitive,这个primitive是否能通过各种culling test(bbox frustum);
- 到了这个阶段,就可以只对这些通过culling的三角形的vertex做计算,在这个阶段每个thread对应一个vertex,fetch 各种attribute并执行各种计算(displacement mapping,计算normal,各种procedure的计算)。这样下来可以节省大量的计算量。
Optimize Topology Connectivity

有了上面的例子大家应该对mesh shading的基本使用有个大致的了解了。接下来讲一下如何用这套pipeline实现我们开头提到的优化拓扑结构,并且把mesh分成小块的meshlet。
首先优化拓扑结构指的是vertex de-duplication/reuse。意思是:假设原来的index buffer是{4, 5, 6, 8,4, 6},其中有一些index是重复出现的;为了重用这些index,遍历这个数组并保留其中没有重复出现的部分,存到vertexIndices这个数组,然后用primitiveIndices这个数组取代原来的triangleIndices,其中0,1,2是vertexIndices的索引。
这样下来我们得到了两个数组,它们表达了整个mesh。从0开始数,每当vertex或者primitive的数量达到一定量的时候,这部分顶点/primitive就被划分到一个新的meshlet。

他们的建议是64个vertex和126个primitive作为上限。126听起来有点怪,这个建议是因为加上一个4字节的primitive count大小接近于128的3倍。
下面是最后处理完得到的数据结构:首先有一个代表整个mesh的primitiveIndices和vertexIndices,然后是一个描述了这些meshlet分块的数据,里面每一项保存了一个meshlet对应的primitiveIndices和vertexIndices的起始位置和长度。这些都是绘制之前预计算好的。
这样重新组织后存储的数据量会小很多,首先vertexIndices的长度比triangleIndices短很多,虽然多了一个primitiveIndices数组,但是这数组的每个元素只要用8-bit的int的保存就好。他们说这样只可以节省75%的数据量。

上面是在运行时,meshshader里处理meshlet的伪代码。实际上写的时候是并行的。
Advantages & Applications
总结一下上面说的使用mesh shading的好处
- 每有一个fixed-function就意味可能的瓶颈;而mesh shading去掉了前面的这些fixed-function阶段,提高了灵活性,摆脱了fixed-function可能带来的瓶颈;
- 可以优化vertex reuse。通过提前的culling减少attribute fetch
- 分成若干的meshlet足够小,使得需要的数据可以尽量存在最靠近的那一层cache上(L1 cache),避免从L2 cache、gpu主存中读;
- 整个pipeline更像compute shader,更加灵活,减少黑盒;

所以,mesh shading会在这些应用上有比较大的用处:
- 比较复杂的mesh,但是大量的三角形都被culling;
- 更好地实现lod,这个后面会结合demo的实现进行介绍;
- procedural instancing,指的是植被、头发、海洋、地形这种生成式的、大量的geometry,利用task shader和mesh shader结合可以更灵活地实现;
- iso-surface,比如各种医学数据、Voxel、 SDF(有向距离场)。绘制这类数据通常需要marching cube这样比较复杂的算法,原本在compute shader里面比较麻烦,现在可以在mesh shader里实现;
Rendering (More) Asteroids
这部分开始讲Asteroids这个demo是怎么做的。
Modelling Asteroids
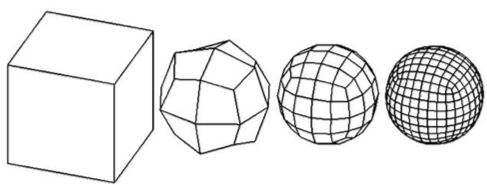
场景中的模型是Mudbox这个软件做的。在制作模型的过程中,从一个简单的cube开始,不断做次表面细分并且雕刻,最后得到带有多级LOD的模型。他们还写了一个导出的插件,应该是把之前说的的meshlet预计算的部分做到导出工具里了。

上图是一个具体的陨石的制作例子。从一个12个三角形的cube开始,不断细分并雕刻,一共细分10次,得到0-10的lod。最后的三角形数非常大。

最后得到了20个不同的陨石模型,按照大小分成4个大类。总的数据量在5.5G左右,尺度在10m到20km之间,可以看出来精细程度非常高。
Stochastic Dithering

上面讲的是如何实现连续的lod切换。首先他们使用的是deferred rendering,所以这些陨石会被绘制到gbuffer上。但是用gbuffer的话不能直接做alpha blending,所以他们用了这种stochastic dithering的方法。他们分别绘制了lod为N和N+1的结果,然后用一张blue noise texture来切换不同lod的结果。
这么简单地做的话会有个缺点:在近处看时,会明显地看到这些noise产生的扰动,所以设定了距离作为trigger;另一方面,实现transition两次绘制又比较耗时,但是不transition导致pop。所以他们通过测试总结最好的transition distance设置,在保证pop不明显的同时尽量减少transitoin distance;(这部分没有听太清楚)
From Sectors to Shaders
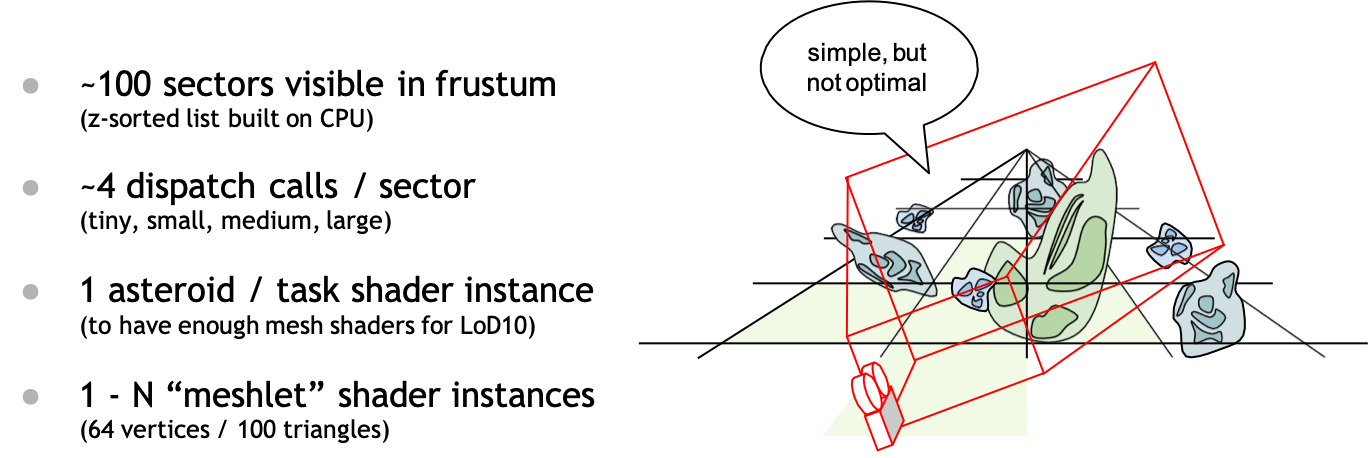
然后来讲场景是怎么绘制的:首先整个平面被划分成多个section,然后cpu端会记录一个在视锥体里的从近到远的sectioin的list;每个sector会发出4个dispatch call,分别负责绘制4种不同大小的陨石(这么做没有什么技术上的缘由,主要是比较好理解/写起来比较方便);每个陨石都有一个特定的task shader来处理,因为它们在做的时候以为一个task shader只能产生最多6500个mesh shader(其实最多有8.5m),为了能够产生足够的用于lod10的meshlet,就简单地设计了这个一对一的关系。但是这么做其实有点浪费task shader的并行性,相当于每个task shader只执行了一个thread。接着每个task shader产生多个mesh shader去处理meshlet。

具体在task shader和mesh shader里面,他们做了gpu上的culling。比起现在一般在cpu做culling的方法,在gpu上做的performance显然要更高。
在task shader里面,首先会根据整个陨石的bounding box做frustum culling;然后会做distance test/fog test,把那些特别远的陨石去掉,因为太远就看不清楚了;他们还做了hierarchical-Z test:他们会先绘制前5个sector,然后取zbuffer来给后续sector的绘制做z test,具体来说是用每个陨石的bounding box看它是不是被遮挡了。
这三个test下来已经能去掉很多不需要绘制的陨石了,到了mesh shader还可以做粒度更细的culling。首先是对meshlet的bounding box做frustum culling;他们还尝试了在mesh shader里再做两种culling,不过他说效果不太好。一个是计算平均的normal来做背面剔除;另一个是再对meshlet的bounding box做hierarchical-Z test。在测试中发现,后面的这两种culling的计算代价比节省的计算量还大。他们总结了一个有用的结论:虽然某种culling理论上来说能够去掉很多不需要的计算量,但是实际上在多个culling test同时作用的过程中,后面的culling test所去掉的很有可能被前面的culling test去掉了,所以实际上的优化效果可能使计算量不降反增。(他的建议是都实现,多测试)

上面是task shader的伪代码,包含了上面说到的各种内容。
- 首先unpack出这个陨石的信息,然后计算bounding box/sphere,投影到屏幕空间,然后做frustum culling。
- 接着计算fade值,让远处陨石从背景逐渐消失或者出现,而不是直接pop出来。然后做之前说的fog test和hierarchical z test。
- 做完各种culling之后,计算lod相关的信息,pack到tasklet里面,最后计算meshlet的数量并通过NvSetMeshCount设置。

上面是mesh shader的伪代码。
- 先去获取group id和thread id,然后用group id获取对应的tasklet,unpack出关于mesh和lod的输入信息。
- 然后做culling。这里只用thread 0来做culling,因为culling只需要做一次。然后将结果share给其他的thread。如果不通过culling test就提前退出。
- 接着按照我们之前说的方法去索引各种顶点属性,然后调用函数设置position、normal、如此类推。每个thread处理一个顶点上的数据。
- 然后设置primitive的三个顶点的index,这次是每个thread处理一个primitive。
- 最后设置输出primitive的数量,结束。
GPU Trace
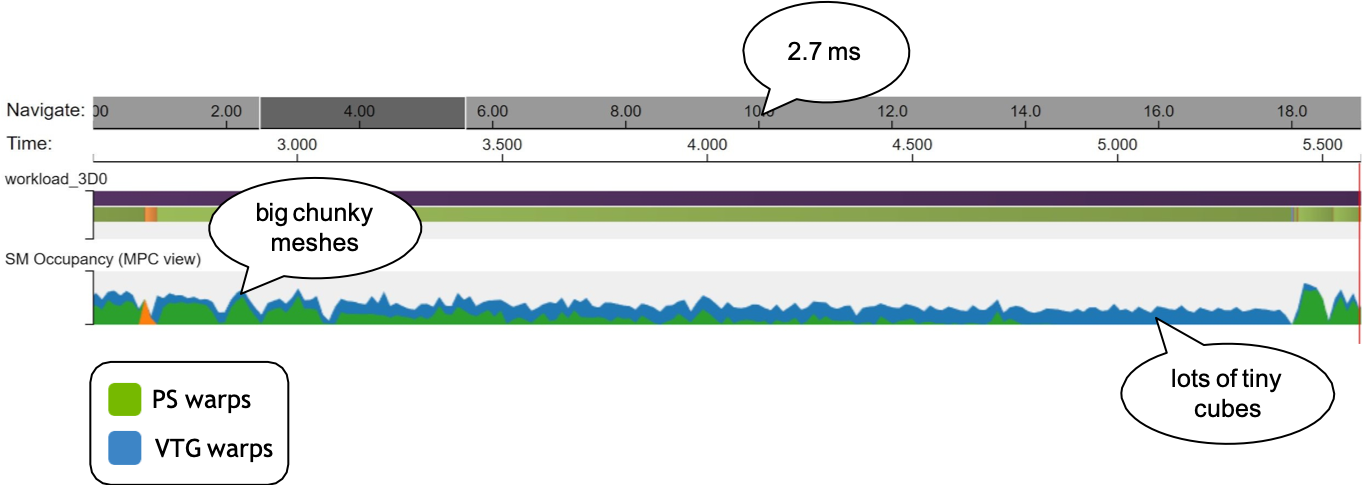
这是用Nsight profile的一个结果。在1080p的分辨率下,绘制gbuffer用了2.7ms。这个图中绿色代表的是pixel shader占用的计算量,蓝色代表task/mesh shader的计算量。可以看出,在一开始的时候计算量主要在pixel shader上,往后pixel shader的占比越来越少,到最后主要是task/mesh shader的计算量,说明culling起了很显著的作用。
Best Practices

这是最后他给的一些建议。
Do:
- 尽量使用task shader。就算你只需要固定数量的mesh shader,用task shader来产生mesh shader也比直接调用mesh shader的performance更好。他的解释是:task shader用多个thread的形式比直接调用dispatch call去调用mesh shader的并行性更好。
- 尽量减少ISBE的大小。这里的ISBE是对写入tasklet和meshlet的数据的总称。尽量通过quantization和packing减少ISBE的大小,能够显著能够性能。
- 尽量做culling。这一点前面已经提到很多了。
Don’t:
- 不要用这套更灵活的pipeline去模拟旧的fixed-function,用最直接的方式解决问题。
- 不要轻易放弃。因为现阶段在这套pipeline下debugging还是比较痛苦的一件事。如果用的是传统的pipeline,你可以在renderdoc里面看到vertex/geometry/pixel shader的各个阶段的输入输出,debug起来比较方便;如果你在mesh shader里写错了什么东西,最后输出primitive的组织形式不对,你可能看到的就是一堆很诡异的东西,也很难看到一些中间结果。
Meshlet Soup

一个有待改善的问题。
上图展示了一个陨石的meshlet的具体分布。可以看到这些meshlet大多又长又细,所以它们的bounding bbox也会又长又细。这样的形状对于做culling来说其实不是那么好(总是露出一部分,进而判断需要绘制整个meshlet)。如果能以一个比较好的方式来组织出比较均匀的meshlet的话,culling的效果会更好。但是这又是一个比较难的问题,所以就只是放在这里作为open problem讲一下。
Meshlet Spriticles

最后简要介绍一些demo里面的其他相关内容。demo里面的每个粒子也是一个meshlet,在mesh shader中以procedural的方法生成。这种方法的速度能够达到传统pipline的方法的速度的两倍。比较特别的一点是:粒子的scatter光照结果是在mesh shader而不是pixel shader里计算的,结果通过meshlet传递给pixel shader直接着色,这样可以节省计算量。(应该是因为粒子很小,可以把整个粒子的颜色当作是一样的)。
References
NVIDIA官网上关于mesh shading和Asteroids的介绍:mesh shading和Asteroids。 NVIDIA这个talk的slides和video可以在这里找到:GDC19-NVIDIA,NVIDIA其他talk的slides和video也在这个页面。